[1,3]\fnmThomas \surIzgin
[1]\orgdivDepartment of Mathematics, \orgnameUniversity of Kassel, \orgaddress\streetHeinrich-Plett-Str. 40, \postcode34132, \cityKassel, \countryGermany 2]\orgdivInstitute of Mathematics, \orgnameJohannes Gutenberg University Mainz, \orgaddress\streetStaudingerweg 9, \postcode55128, \cityMainz, \countryGermany 3]\orgdivDivision of Applied Mathematics, \orgaddress\orgnameBrown University, \cityProvidence, \stateRhode Island \postcode02906, \countryUSA
A Positivity-Preserving Relaxation Algorithm
Abstract
We combine Patankar-type methods with suitable relaxation procedures that are capable of ensuring correct dissipation or conservation of functionals such as entropy or energy while producing unconditionally positive and conservative approximations. To that end, we adapt the relaxation algorithm to enforce positivity by using either ideas from the dense output framework when a linear invariant must be preserved, or simply a geometric mean if the only constraint is positivity preservation. The latter merely requires the solution of a scalar nonlinear equation while former results in a coupled linear-nonlinear system of equations. We present sufficient conditions for the solvability of the respective equations. Several applications in the context of ordinary and partial differential equations are presented, and the theoretical findings are validated numerically.
keywords:
Positivity preservation, Relaxation methods, Entropy stabilitypacs:
[MSC Classification]65M06, 65M08, 65M20,65M22
1 Introduction
We consider initial-value problems (IVPs)
| (1) |
either as classical ordinary differential equation (ODE) model on its own, or more typically obtained after discretizing a partial differential equation (PDE) in space. We are interested in two types of structures of the IVP (1). First, many applications require positive solutions, i.e., for all if , where inequalities are understood component-wise. This occurs, for example, when modeling chemical reactions, population dynamics, or the density of fluids. Second, many problems are equipped with additional functionals of interest, such as Lyapunov functionals, energy, or entropy. We say that the IVP (1) is dissipative with respect to a smooth functional , if , i.e.,
for all solutions of (1). Similarly, (1) is conservative with respect to , if , i.e.,
In addition to the (typically nonlinear) functional , many problems also conserve additional linear invariants, such as mass or momentum, which we also want to preserve on the discrete level.
When discretizing (1) in time using a one-step method, we would like to preserve these properties, i.e., we would like to have an unconditionally positive method satisfying
For many positive ODEs/PDEs, avoiding negative approximations is critical; such artifacts can lead to qualitatively incorrect solutions or the total failure of the numerical method [BBKS2007, sandu2001positive, STKB2005, SSPMPRK2]. Moreover, for dissipative problems, we would like to use a dissipative method that satisfies
| (2) |
Similarly, a conservative method applied to a conservative problem should satisfy
| (3) |
For convex , the implicit Euler method is a well-known example of an unconditionally positive and dissipative method. However, this analysis neglects possible positivity issues that can arise while solving the implicit equations as well as remaining errors of the nonlinear iterative solver.
Concerning positivity, the implicit Euler method is essentially the best method one can use in the class of general linear methods, since any unconditionally positive method can be at most first-order accurate [bolley1978conservation]. To address this challenge, several strategies have been proposed:
-
1.
Clipping techniques, which forcibly set negative values to zero, either result in a mass-shifting optimization problem or otherwise compromise conservation of linear invariants, and, to date, lack a proof of stability [BIM2022].
-
2.
Projection techniques [sandu2001positive, nusslein2021positivity] can be positive and conserve linear invariants, but they may result in step size constraints and/or reduced accuracy.
-
3.
Fully implicit, nonlinear methods [HR2020, ricchiuto2011habilitation] can enforce positivity but require costly iterative solvers, which may fail to converge (to a positive solution), and thus, still produce nonphysical results.
-
4.
Diagonally split Runge–Kutta (DSRK) methods [horvath_positivity_1998] can be unconditionally positive and with order higher than one. However, they are typically less accurate than the implicit Euler method in practice [macdonald2007].
-
5.
Adaptive methods [STKB2005] use root-finding procedures and adapt the time step size. This can be effective, but the resulting schemes are only conditionally positive.
-
6.
Strong stability preserving (SSP) methods [GKS2011] are positive if the explicit Euler method is positive under a certain time step restriction. However, only the implicit Euler method leads to unconditional positivity, and thus, all other SSP methods are only conditionally positive.
-
7.
Patankar-type methods represent a family of explicit or linearly implicit yet nonlinear schemes, which are unconditionally positive and can preserve certain linear invariants [Patankar1980, BDM2003, MCD2020, KM18, AKM2020].
In this work, we focus on Patankar-type schemes. The main idea behind them is to modify an existing time-stepping method by introducing nonlinear weights in such a way that the resulting numerical scheme becomes unconditionally positive. The primary challenge lies in designing these weights so that the modified scheme preserves the accuracy of the original (baseline) method. This nonlinear modification is achieved using the so-called Patankar-trick [Patankar1980], which gives this family of methods its name. A notable example is the incorporation of modified Patankar (MP) weights into classical Runge–Kutta (RK) schemes, leading to the development of modified Patankar–Runge–Kutta (MPRK) methods [BDM2003, KM18, KM18Order3], which in addition to being unconditionally positive, are also conservative. Motivated by their strong numerical performance, the Patankar-trick has since been successfully extended to a variety of time integration frameworks, including SSP Runge–Kutta (SSPRK) methods [SSPMPRK2, SSPMPRK3], arbitrary high-order Deferred Correction (DeC) schemes [MPDeC], generalized BBKS methods [AKM2020], GeCo schemes [MCD2020], and linear multistep methods [IMPV2025]. The resulting modified schemes all belong to the broader Patankar-type family, which can themselves be recast as non-standard additive Runge–Kutta (NSARK) methods, see [NSARK, IzginThesis].
Concerning the preservation (conservation/dissipation) of functionals , several results are available for linear schemes such as RK methods applied to linear problems [tadmor2002semidiscrete, ranocha2018L2stability, sun2017stability, sun2019strong, achleitner2024necessary, tadmor2025stability, sun2022energy] and fully-implicit methods [lefloch2002fully, friedrich2019entropy, burrage1979stability, burrage1980nonlinear, dahlby2011preserving]. There are also positive results on dissipative schemes if the problem is sufficiently dissipative [higueras2005monotonicity, jungel2015entropy, jungel2017entropy]. In the general case including conservative problems, however, results are restrictive and include many negative results [ranocha2021strong, ranocha2020energy]. Similarly to positivity preservation, postprocessing/projection methods can be used to enforce the desired conservation/dissipation properties of time integration methods [Shampine1986, grimm2005geometric, calvo2006preservation, calvo2010projection, laburta2015numerical]. In this work, we focus on the relaxation approach [ketcheson2019relaxation, ranocha2020relaxation, ranocha2020general], which can be used to enforce conservation/dissipation of functionals while preserving all linear invariants. The basic idea of relaxation methods goes back to [sanzserna1982explicit] and [dekker1984stability, pp. 265–266].
Thus, there are several studies and methods devoted to either positivity preservation or the preservation of functionals such as entropy, but to the best of our knowledge, there is no high-order method that can guarantee both properties simultaneously. The main contribution of this work is to design a modified relaxation algorithm capable of simultaneously preserving positivity and conservation/dissipation of functionals. To that end, we first equip unconditionally positivity-preserving NSARK methods with suitable estimates for dissipative entropies by applying the relaxation framework from [ranocha2020general]. While relaxation can be rendered positivity-preserving for dissipative problems with minor adjustments (see Remark 3), entropy-conservative problems require more sophisticated treatment. Leveraging dense output formulae for MPRK methods [izgin2024], we propose a modified relaxation step that ensures unconditional positivity. Furthermore, we introduce a bootstrapping technique to achieve arbitrarily high-order accuracy in time for MPRK schemes.
The remainder of the paper is structured as follows. We recall the relaxation technique from [ranocha2020general] in Section 2.1. In Section 2.2 we give a brief introduction to NSARK methods. After that, we explain in Section 3.1 how to apply the relaxation algorithm for NSARK schemes and entropy dissipative problems. The main result is given for the entropy-conservative case, see Section 3.2, where we equip different families of MP schemes with a positivity-preserving relaxation algorithm and present a bootstrapping technique to obtain arbitrary high order (in time) for MPRK schemes. Finally, we present several examples of ordinary and partial differential equations and validate our findings for second- and third-order MP schemes.
2 Preliminaries
In this section, we briefly review relaxation methods to preserve functionals and non-standard additive Runge–Kutta (NSARK) methods, which includes Patankar-type methods as a special case.
2.1 Classical Relaxation
One way to guarantee dissipation (2) or conservation (3) of functionals is the relaxation procedure explained in [ranocha2020general]. We are given a numerical one-step method of order generating approximations to with a time step size of . We then have to repeat the following steps, starting with .
-
1.
Define the quantities as well as .
-
2.
-
•
For dissipative problems (1) compute a suitable estimate
-
•
For conservative problems we can simply set , since we arrive at by means of an induction over .
-
•
-
3.
Solve the system
(4) by inserting into the last equation and solving for , and then computing and according to the remaining equations.
-
4.
Proceed with the numerical scheme using and instead of and .
For dissipative problems, the “suitable estimate ” must guarantee the discrete dissipativity (2) for the approximations from the relaxation procedure. We will introduce such a suitable estimate for NSARK methods that are based on ARK methods with a non-negative extended Butcher tableau in Section 3.1. For now, let us proceed by revisiting the main results from [ranocha2020general], assuming we have such an at hand.
Theorem 1 ([ranocha2020general, Theorem 2.13, Theorem 2.14]).
This theorem is the theoretical basis for the existence and uniqueness of the solution of the relaxation procedure (4). Unfortunately, the theorem does not give bounds on for the existence of the solution, so that computations may be rejected due to being too large.
Remark 1 (Issue with positivity).
The main issue of positivity-preservation with the above relaxation algorithm is that the update
is not necessarily positivity-preserving for , even if the baseline method is positive.
Nevertheless, to overcome this issue, we propose to use unconditionally positive111That is, component-wise implies for all . time integrators. In the upcoming sections, we introduce the methods of interest for this work, all of which may be recast as so-called non-standard additive Runge–Kutta schemes.
2.2 Non-standard Additive Runge–Kutta Methods
Non-standard additive Runge–Kutta methods (NSARK) methods are applied to an IVP (1), where the right-hand side is split into a sum, that is
| (7) |
Already for traditional additive Runge–Kutta (ARK) methods, including Implicit-Explicit (IMEX) Runge–Kutta (RK) methods [Crouzeix1980, ARS1997], the main idea is to apply very different RK schemes determined by , , to the different addends . For internal consistency, we require that the different RK schemes actually do not differ in the abscissa, i.e.
| (8) |
for and , see [SG2015]. However, for autonomous IVPs (7), this has no effect on the resulting ARK method, which in this case reads
| (9) | ||||
and the corresponding extended Butcher tableau is given by
with .
NSARK methods now differ from ARK schemes (9) in that their extended Butcher tableau is allowed to also depend on the step size and the solution. In particular, NSARK methods applied to (7) are of the form
| (10) | ||||
where .
In the case of gBBKS [AKM2020], Geometric Conservative (GeCo) [MCD2020], both of which may be interpreted as NSRK schemes, as well as modified Patankar–Runge–Kutta (MPRK) [KM18, KM18Order3] methods, the same RK scheme is used for the treatment of the different addends in (7) and only the solution-dependent terms vary. For MP strong-stability-preserving RK (MPSSPRK) schemes, the situation is different, see Section 2.2.3. In this work we focus on modified Patankar (MP) schemes in the entropy-conservative case and leave gBBKS and GeCo methods for future works.
2.2.1 Production-Destruction-Rest Systems
The application of modified Patankar (MP) schemes is restricted to production-destruction-rest (PDRS) systems
with and on . We note that this is only a formal restriction since every autonomous system with real-valued right-hand sides can be rewritten as such a PDRS [IR2023]. Now, one can recover the function in (7) and specify the solution-dependent Butcher coefficients. Indeed, according to [IzginThesis, Remark 2.25], a PDRS can be written in terms of (7) by using the convention and choosing as well as
| (11) | ||||
for .
2.2.2 Modified Patankar–Runge–Kutta Schemes
With (11), every MPRK scheme [BDM2003, KM18, KM18Order3] that is based on a single explicit RK method with a non-negative Butcher array can be expressed in terms of an NSARK scheme using
| (12) | ||||
where
| (13) | ||||
are the so-called non-standard weights (NSWs). Here, and denote the so-called Patankar-weight denominators (PWDs) and can be chosen for the particular MPRK method to ensure stability and accuracy, see [KM18, IzginThesis] for more insights. If the Butcher array contains negative entries, more care is needed when defining the MPRK method, see e.g. [MPDeC].
Example 1 (Second-order Family).
The second-order family of MPRK schemes, denoted by MPRK22(), is given by
with , and as well as . In terms of the previous notation, we are using the Butcher array
and the PWDs
In this work, we will focus on as suggested by [IssuesMPRK].
Example 2 (Third-order Family).
There are two third-order families of MPRK schemes, see [KM18Order3]. One of them is based on the Butcher array
| (14) |
see [KM18Order3] for more details on the domain of and . The PWDs are given by
| (15) | ||||
for , where , , and . Note that requires the solution of another linear system, which is why this family is denoted by MPRK43I(). In this work we focus on and .
In any case we point out that the schemes are implicit due to the numerators in (13). Indeed, they are linearly implicit as the PWDs and are required to be independent of the numerator [BDM2003, IzginThesis]. Consequently, an MPRK scheme can be written in matrix-vector notation as follows.
| (16) | ||||
where and with
| (17) | ||||
as well as, using ,
| (18) | ||||
2.2.3 MP Strong-Stability-Preserving-Runge–Kutta Schemes
Although there exist second- and third-order MPSSPRK schemes, see [SSPMPRK2, SSPMPRK3], we focus for simplicity on the second-order method and the conservative PDS case. The generalization to non-conservative PDRS is straightforward but complicates the formulae. Also, the consideration of third-order MPSSPRK schemes will be left out for future work. The two-parameter family of second-order MPSSPRK schemes from [SSPMPRK2] is given by
| (19) | ||||
where , and . There, the free parameters and are subject to
| (20) |
We refer to the above scheme as MPSSPRK2(). For numerical experiments we use and [SSPMPRK2].
Substituting the second stage into the update, we can collect production and destruction terms. Hence, in the notation of (11), the solution-dependent coefficients for the conservative PDS case are
| (21) | ||||
where .
3 Positivity-Preserving Relaxation Technique
In what follows, we adapt the classical relaxation algorithm from Section 2.1 such that it becomes positivity-preserving.
3.1 Entropy Dissipative Case
First of all, we present a suitable estimate for a general NSARK scheme. In order to minimize the computational effort, we propose to re-use the computed stage values of the NSARK scheme satisfying (12), that is
| (22) | ||||
which can be interpreted as computing the numerical approximation of the augmented system
using an NSARK method with the extended Butcher tableau
| (23) |
where . Assuming that the two corresponding base methods described by the Butcher tableaux
both are of -th order for some , it can be seen from [NSARK, Theorem 18,Lemma 25,Lemma 26] that the overall scheme (22) is of order , since the respective order conditions are decoupled with respect to the columns of the tableau (23).
Remark 2.
As a result, we indeed obtain that , and additionally,
| (24) |
whenever for . If for some , one can still use Gauß quadrature, as suggested in [ranocha2020general, Page 866] together with the unconditionally positive dense output formulae derived in [izgin2024] to obtain the approximations needed for the quadrature formula.
In view of Remark 1, the relaxation technique is in danger of not being positivity-preserving for . The following corollary gives a work around for dissipative problems as we will discuss in the upcoming Remark 3.
Corollary 1 ([ranocha2020general, Pages 882-883]).
If is convex with then from (6) is convex and satisfies , and for all and small enough.
Remark 3 (Positivity-preserving relaxation for convex ).
Suppose that is the solution to (4), i.e. , so that the positivity of the relaxation update is not guaranteed any longer. Because of Corollary 1 we know that for all . In particular follows, i. e., for we obtain from (6) the relation
This means, that due to (24) only more dissipation will be introduced by using
where is the solution to (4). But with that choice, is again a convex combination of positive data, and hence, positivity preservation is guaranteed for dissipative problems with a convex .
3.2 Entropy-Conservative Case
As in (4) is not guaranteed to be positivity-preserving for , see Remark 1, we propose to replace the update formula by a positivity-preserving variant. To indicate this difference in our notation we will write for a positivity-preserving approximation rather than .
3.2.1 Explicit Positivity-Preserving Procedure
If we are only interested in preserving positivity, a single nonlinear invariant but no further linear invariants, we may apply a Patankar–Runge–Kutta method to guarantee the positivity of the update and combine it with the geometric mean
| (25) |
In logarithmic variables, this reduces to
where we can find a solution to the relaxation problem in logarithmic variables according to the classical theory. Now, if is convex and non-decreasing in each argument the composition is also convex [boyd2004convex, Section 2.3.4], and hence, also
possesses a positive solution .
3.2.2 Implicit Positivity-Preserving Procedure for Conservative PDS
One possible candidate for computing is to use dense output formulae recently developed in [izgin2024], which we briefly recall in the upcoming section.
Positivity-Preserving Dense Output
We first focus on Runge–Kutta methods and the MP variant, but the ideas can be carried out for MPSSPRK schemes in a straightforward manner as we will see.
The main idea is to replace by a function such that
approximates . We impose
to recover
Example 3 (Second-order dense output for MPRK22()).
Using and
yields a positivity-preserving dense output. Indeed, we find in this case, which coincides with the relaxation update. For this is not necessarily positivity-preserving. For our purposes, we want to ensure positivity even for , which can be done using
| (26) |
together with
| (27) |
or
| (28) |
Example 4 (Higher order positive dense output for MPRK).
In general, one may use from the classical dense output formula paired with the update (26). Then, the only quantity to define is . According to [izgin2024], it is sufficient to use a lower order dense output MPRK scheme for the computation of . For instance, we note that third-order MPRK schemes are equipped with
for the dense output. However, we will discuss a different approach in this work, and thus, omit to also recall from [izgin2024].
Example 5 (Second-order dense output for MPSSPRK).
Remark 4 (Use of dense output for relaxation).
As we will show, we can use the dense output from Example 3 for the relaxation algorithm. However, proving the existence of a solution to the relaxation equation for (27) is more complex than for (28), which is due to the respective truncation errors. Moreover, as illustrated in Example 4, the bootstrapping for higher order positive dense output involves higher degree polynomials for , which may not be positive for . This is crucial since the solvability for the linear systems (16) relies on positive Butcher coefficients. While we could implement a trick [MPDeC] to overcome this issue, we rather focus on a different bootstrapping approach to keep the overall algorithm simple.
Preparatory Results for MPRK22()
We proceed to develop a relaxation technique using (26)-(27), which is more complicated than using (28) but on the other hand motivates us to derive more general results. To that end, we note that the scheme with (26)-(27) can be written in matrix-vector notation as
| (29) | ||||
where can be obtained from (17) and
| (30) |
with from (18).
Finally, the relaxation step (4) for entropy-conservative problems is now updated to
| (31) |
resulting in a coupled linear-nonlinear system for the simultaneous computation of and . Note that if such a exists, the relaxation method for MPRK22() naturally is of the correct order for all as we are using an appropriate dense output formula.
Since we allow for a truncation error of for the second-order MPRK22) scheme, it is beneficial to prove the following
Lemma 1.
Proof.
Utilizing [KM2019, Lemma 2, Lemma 3], we observe
| (34) |
as [NSARK]. Substituting this into (26) we receive
∎
Remark 5 (Influence of and application to MPSSPRK).
In the situation of Lemma 1, if we use (28) rather than (27), then instead of (34) we obtain
using the same technique, and finally
| (35) |
Here is independent of . We note that the PWDs for MPSSPRK2 are similar to the MPRK case, see Section 2.2.3. Indeed, one can show that (35) also holds for the second-order MPSSPRK family.
Main Result for Entropy Conservation and Positivity Preservation
We assume that the method can be written in the form
with being the order of the baseline method and some suitable depending on the method. Now, since generally also depends on , we need the preparatory
Lemma 2.
Let ,
| (36) |
where is an open neighborhood of .
If is a map on w.r.t. with for small enough, then there exist a neighborhood of and a continuous function such that for all and small enough.
Proof.
We have and
Thus, for small enough. The assertion then follows from the implicit function theorem. ∎
With that, we are positioned to prove the main theorem for the relaxation technique.
Theorem 2.
In the situation of Lemma 2, let
with being the order of the baseline method and suppose with
for small enough and
Then the equation
possesses a positive solution . Furthermore, if , then there exists a unique positive solution satisfying .
Proof.
We set
and follow the proof of [CLM2010, Theorem 2] by analyzing the function
| (37) |
The idea is to deduce that
| (38) |
where denotes the Hessian. Then, since , we have
According to the proof of [CLM2010, Theorem 2], there exist and a unique function such that for all . Indeed, because of
it can be deduced along the same lines that .
To prove (38) we first note that
| (39) |
where
| (40) |
Next, as we can use Lemma 2 to solve (40) for and plug it into (39) resulting in a function of only, i.e.
In the following, we denote by the exact local solution at satisfying and recall that we are considering an entropy-conservative problem. Hence, with and the assumptions on we receive
Finally, since we deduce that . ∎
Now if we are given such a solution we can deduce that the relaxation update is of order as the following lemma shows.
Lemma 3.
If with a -th order baseline method and , then
Proof.
This is just Lemma [ranocha2020general, Lemma 2.7], where the relaxation method is perturbed by an additive error of . ∎
Bootstrapping Algorithm for Positivity-Preserving Relaxation
The main idea for generalizing the relaxation technique to higher order is to use the observation from Remark 5, where
Since now is independent of , there is no need for Lemma 2 as we have an explicit expression for , i.e. and we can apply Theorem 2 giving us . Also, Remark 4 motivates us to start a bootstrapping algorithm using the functions also for higher order. This seems to contradict our results from the theory on dense output, but in combination with relaxation, the issue can be resolved, see Remark 6 below.
Now in view of the following lemma, we can bootstrap the relaxation technique to higher orders.
Lemma 4.
Consider a scheme of the form (26) with and
| (41) |
for all in a neighborhood of . Then
and in particular,
for all .
Remark 6.
Before we prove this lemma, we want to stress two things. First, using (41) with does not result in a higher-order dense output formula, but only guarantees to obtain the desired order at the root of , see Theorem 2 and Lemma 3.
Secondly, the bootstrapping process consists of using from the scheme of order as the new resulting in a new method of order . We can start the bootstrapping process by using the second-order MPRK22() scheme as a baseline method together with (28). Note that this naturally results in nested functions that depend on , which should be kept in mind when implementing the Newton iteration.
Proof of Lemma 4.
We prove this claim by induction over and exploit [IzginThesis, Lemma 4.6,Lemma 4.8] to justify the implication
For we find and since due to [IzginThesis, Lemma 4.6].
Example 6 (Third-Order Relaxation for Conservative Problems using MPRK).
Looking at the third-order MPRK family from Example 2, the relaxation scheme is fully defined by setting
| (42) | ||||
for , , and .
Applying Newton’s Method
Starting with (43) we deduce
To rewrite this in matrix-vector notation, we denote by “” and “” the component-wise division and multiplication (Hadamard division and product), respectively. Then, using
we end up with
| (45) |
Note that if , then . Also note that the derivative of from (42) itself satisfies an analogue equation to (45) as it represents an MPRK22() relaxation method of order .
Also, the system for MPSSPRK22 is the same; one only has to plug in the expressions and for that particular scheme.
4 Numerical Experiments
In this section we apply our new relaxation algorithm to dissipative and conservative problems to validate our theoretical findings and to experimentally test the constraints on for solving the system (31). We note that we use Newton’s method for the computation of , if not stated otherwise. Also, we use (27) as default for MPRK22). Also, we may use a PID controller with parameters , , and , see [IR2023] for more details. The resulting method is denoted by MPRK22adap. We note that our implementation of the relaxation algorithm, which can be found in our reproducibility repository [IRS2026repository], is also adaptive in the sense that successful relaxation steps increase the by 1% while unsuccessful searches for result in a 10% decrease of the time step size. We refer to the repository [IRS2026repository] for the implemented abortion criteria.
4.1 Lotka-Volterra System
The classical Lotka-Volterra system
can be written as a non-conservative PDRS with
The entropy
is conserved. Since the Lotka-Volterra system has periodic orbits, we expect improved numerical results using relaxation to conserve the entropy [cano1997error, cano1998error, calvo2011error].






Although there are only positivity constraints, is not non-decreasing for all in this example, which is why we use the default relaxation algorithm. As expected, we observe that relaxation improves the error growth of the base method from quadratic to linear, see Figure 1.
4.2 Stratospheric Reaction Problem
The stratospheric reaction problem [sandu2001positive] is a stiff system of ODEs describing the interaction of the constituents . This non-conservative PDS possesses two linear invariants determined by the vectors and . In order to apply MPRK schemes to this problem, we scale the corresponding differential equations writing
Hence, introducing , the two linear invariants of the differential equations are and . Moreover, the scaled system takes the form
| (46) | ||||
where
as well as
The non-zero production and destruction terms of the system (46) are given by
and . The solution to this problem will be approximated over the time interval , where a unit of time represents a second. A reference solution of the scaled problem is depicted in Figure 2.

As we will see, MPRK schemes do not conserve the second linear invariant, which is why
with . Hence, we may use
as an entropy function satisfying (5) to preserve also the second linear invariant with our relaxation technique for conservative problems. As can be seen in Figure 3, using relaxation improves the accuracy of the solution significantly. However, we note that Newton’s method, while working in principle, sometimes fails at finding a solution in our implementation. Indeed, we observed and thus decided to use Regula Falsi as a solver.






4.3 Linear advection
Consider the linear advection equation
| (47) |
with periodic boundary conditions on and a positive initial condition . Then, the solution stays positive. Moreover, every functional of the form
| (48) |
for an entropy function is conserved with associated entropy flux . Following Tadmor [Tadmor03], the entropy variables are and the flux potential is . The corresponding entropy-conservative numerical flux is
| (49) |
If faster than as , then the numerical flux goes to zero if one of the states goes to zero. Therefore, the resulting finite volume method
| (50) |
is positivity-preserving in this case. In particular, the numerical fluxes are always non-negative, resulting in a conservative production-destruction system. Next, we consider several examples.
-
•
The entropy
(51) leads to the entropy-conservative numerical flux
(52) using the logarithmic mean, see [ranocha2021preventing, Section 3.2].
-
•
Similarly, the entropy
(53) leads to the entropy variables , the flux potential , and the entropy-conservative numerical flux
(54) using the geometric mean.
-
•
Analogously, the entropy
(55) leads to the entropy variables , the flux potential , and the entropy-conservative numerical flux
(56) using the harmonic mean.
Please note that positivity preservation for an entropy-conservative method depends on the choice of the entropy function. For example, the standard entropy
| (57) |
leads to the numerical flux
| (58) |
i.e., the standard arithmetic mean. The resulting finite volume discretization
| (59) |
is the classical second-order central discretization, which is not positivity-preserving.
We use cells and the initial condition
and apply different iterative methods for solving for . The respective results are depicted in Figure 4.






4.4 Shallow water equations
The classical shallow water equations
| (60) |
have the total energy
| (61) |
as entropy. The corresponding entropy variables are
| (62) |
and the entropy flux potential is
| (63) |
For constant velocity , the condition for an entropy-conservative numerical flux is
| (64) |
where . Thus, the numerical flux for the water height is
| (65) |
with the arithmetic mean
| (66) |
Similarly to the linear advection equations above, the arithmetic mean does not lead to a positivity-preserving semidiscretization. This proves
Theorem 3.
An entropy-conservative semidiscretization of the shallow water equations is not positivity-preserving.
One can show a similar result for the polytropic Euler equations with pressure and . However, the limiting case of the isothermal Euler equations is different and discussed in the next subsection.
4.5 Isothermal Euler equations
The 1D isothermal Euler equations are
| (67) |
where is the density, is the velocity, and is the speed of sound. We take the total energy
| (68) |
as (mathematical) entropy. An associated entropy-conservative numerical flux at the interface is given by [winters2020entropy]
| (69) |
Since the logarithmic mean goes to zero if one of the states goes to zero, the resulting entropy-conservative finite volume method is unconditionally positive. Even more general, the flux differencing method [tadmor1987numerical, Tadmor03, lefloch2002fully, fisher2013discretely, ranocha2018comparison, chen2017entropy] based on diagonal-norm SBP operators. In particular, high-order discontinuous Galerkin spectral element methods (DGSEMs) are positivity-preserving. While we apply the underlying explicit RK method to the second conserved variable together with the standard relaxation algorithm, we use MPRK22 for , where we use the PDS
for and we take periodic boundary conditions into account for the terms if . The study of flux-balanced MPRK schemes introduced in [IMST2026] is left for future works. In Figure 5 we solve the Riemann problem (RP)
with periodic boundary conditions and final time . We note that one should not use an entropy conservative flux for an RP, however, this is a good example that our time integrator maintains the entropy properties of the space discretization.



4.6 Porous Medium Equation
The porous medium equation
with a free parameter , see for instance [Boscarino23], admits a non-negative weak solution
with , the so-called Barenblatt solution [Barenblatt52]. For every , the solution has a compact support where
We follow [Boscarino23] using as an initial condition. We plot the numerical solution at time on the spatial domain using the boundary conditions for .
We use the second-order space discretization from [Mattsson12, ranocha2019mimetic] given by
for and
Next, we consider the convex entropy
which satisfies
for the boundary conditions mentioned above, see [ranocha2019mimetic, Theorem 4.1]. This system of ODEs may be rewritten as a conservative PDS by setting
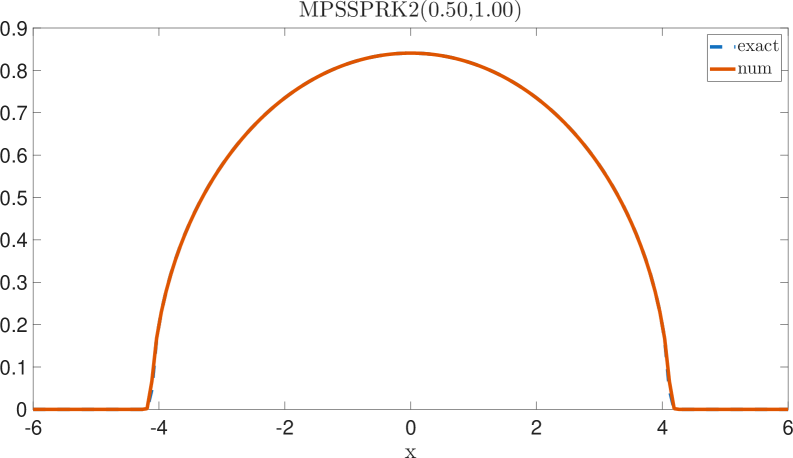
According to [Boscarino23], the cases are particularly interesting as the numerical solution of the proposed third-order IMEX method in [Boscarino23, p. 10, eq. (30)] generates negative approximations and which cannot happen with MPRK schemes. Indeed, we observe in Figure 6 that we obtain positive approximations while the relaxation algorithm gives us an entropy estimate. Here, we do not plot as it was constantly at .



5 Summary and conclusions
In this work we investigated non-standard additive Runge–Kutta (NSARK) schemes, which include modified Patankar (MP) methods or Geometric Conservative (GeCo) to name a few. Being particularly interested in positivity-preserving methods that are also capable of conserving at least one linear invariant, we answered the question of whether these schemes can be equipped with a relaxation technique that preserves these properties while ensuring entropy stability. We point out that positivity preservation is easy to accomplish for entropy dissipative problems. For entropy conservative problems, where no linear invariant needs to be preserved, one can equip an unconditionally positive method with the geometric mean to compute the relaxation update. If the conservative problem has a linear invariant or one is interested in keeping a conservative PDS part also conservative within the relaxation procedure, we propose to use a linearly implicit formula for the relaxation update, which in turn results in a coupled linear-nonlinear system for the simultaneous computation of and . All techniques can be used for any positivity-preserving method maintaining the order, however, the latter relaxation technique involves a bootstrapping algorithm to achieve higher-order entropy conservative methods preserving a linear invariant.
We have tested our theoretical findings by means of multiple examples of ordinary and partial differential equations. Furthermore, interpreting a linear invariant as entropy, we were able to preserve both linear invariants of the stiff stratospheric reaction problem using MPRK. We have also tested several flux and entropy pairs for the linear advection equation testing the different iterative solvers for the computation of and . Moreover, we applied our technique also in the context of the isothermal Euler equation guaranteeing the positivity of the density. Finally, we have also tested MPRK and MPSSPRK schemes with the entropy dissipative porous medium equation, where we are also able to avoid negative approximations.
Future research topics include the testing of further NSARK schemes, including the recently developed flux-balanced versions, and the efficiency of the related methods. As some of the NSARK schemes are already proven to be conditionally stable, a thorough stability analysis for these methods is also part of ongoing research.
Acknowledgements
Declarations
Funding
T. Izgin gratefully acknowledges the financial support by Fulbright Germany. H. Ranocha was supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation, project number 513301895) and the Daimler und Benz Stiftung (Daimler and Benz foundation, project number 32-10/22). C.-W. Shu acknowledges partial support from NSF grant DMS-2309249.
Conflict of interest
Not applicable.
Ethics approval and consent to participate
Not applicable.
Consent for publication
All authors consent to submit for publication.
Data, Materials and Code availability
The source code used in this study is available at [IRS2026repository].
Author contribution
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Thomas Izgin. The first draft of the manuscript was written by Thomas Izgin and all authors commented on as well as wrote on previous versions of the manuscript. All authors read and approved the final manuscript.